
苹果公司最近推出了一项创新技术——降噪语言模型(DLM),通过大量合成数据训练,实现了自动语音识别(ASR)领域的最新性能突破。
这项技术的核心是使用文本转语音(TTS)系统创建音频,并将其输入ASR系统,从而产生嘈杂的假设音频。这些假设音频与原始文本进行配对,用于训练DLM。该方法的关键要素包括模型和数据的升级、多说话人TTS系统、多种噪声增强策略以及新的解码技术。
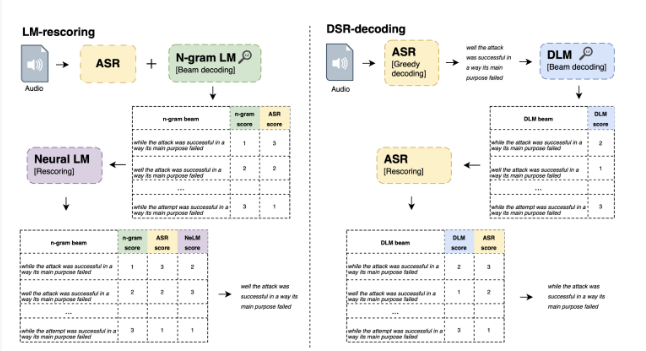
研究表明,单个DLM可以应用于不同的ASR系统,其性能显著优于传统的基于语言模型(LM)的集束搜索重新评分方法。这一突破表明,精心设计的纠错模型可以替代传统的LM,将ASR系统的准确率提升到一个新的高度。尤其值得注意的是,DLM在LibriSpeech数据集上实现了1.5%的字错误率(WER),这是不使用外部音频数据时报告的最佳成绩之一,充分展示了其卓越性能。
DLM面临的一个主要挑战是需要大量的监督训练示例,而这在典型的ASR数据集中是有限的。为了解决这一问题,DLM采用了TTS系统生成合成音频的方法,从而扩展了训练数据集的规模。这种创新性的方法为DLM的性能提升提供了更广阔的空间,使其在ASR领域保持领先地位。
总之,苹果的DLM通过有效纠正ASR系统中的错误,显著提升了语音识别的准确率,标志着ASR技术的又一次重大进步。这一创新不仅提升了用户体验,还为未来的语音识别技术发展奠定了坚实基础。





